DARE / Resolution
The first response
is the audition.
What 9 customers and 10 pros told us about AI-assisted initial responses on Thumbtack.
~10 min read
What the two studies, together, tell us
-
01
The first response carries more leverage than we previously gave it credit for.
The LLM-assisted Response Quality Investigation (RQI) positioned follow-up as higher leverage than first-response on the assumption that many first responses never reach a decision threshold. Customer concept testing sharpens that: once a customer has 2–3 viable pros in hand, the lower-ranked responses have no recovery path. The first response is effectively the audition. This doesn't invalidate follow-up as a learning surface, but it raises the bar on what v1 of this work has to get right.
-
02
"Acknowledgment + one bounded next step" replicates as the success pattern — with two critical refinements.
(a) Acknowledgment has to be lightweight — 1–3 high-signal details, varied across pros, not a transcript of the request form. Over-mirroring feels mechanical and breaks the trust signal it's meant to create. (b) The bounded next step should be a question, not a declarative statement, so the cognitive cost of replying is low and the ball is in the customer's court.
-
03
"No next step" is an unrecoverable failure. Ignoring a stated detail is an unrecoverable failure.
These are the two hardest failure modes across all 9 customer sessions. Everything else is gradient.
-
04
Pros preferred the toggled draft (Concept 2), but the mechanism is trust, not performance.
The toggles didn't change what pros sent so much as how confident they felt sending it. Since C2 can't ship in v1 on the current timeline, the plain draft must clear a higher bar on accuracy and voice to compensate — pros who don't trust the output will delete it or disable the feature.
-
05
Anti-redundancy across pros is a product requirement, not a nice-to-have.
Both sides surfaced this independently: customers detect AI when multiple pros send near-identical messages; pros refuse to adopt a tool that flattens their differentiation. Currently scoped P1 — the research suggests it's closer to P0 for adoption.
-
06
Credibility is behavioral, not boilerplate.
Generic credibility signals ("highly experienced technicians," "top reviews") are largely invisible by the time the customer is reading the message — they've already seen reviews on the SP. What builds trust in-message is demonstrating competence through the right question.
Note: the original Pro 7 archetype definition included "implicit credibility via question quality" as the credibility mechanism. In other words, credibility was always coded behaviorally rather than through self-promotional language. What the customer sessions confirmed is that this mechanism works — when pros asked a question that demonstrated they understood the job (e.g., mentioning 60-gallon vs. 40-gallon water heater), customers read that as more credible than "highly experienced technicians with top reviews." The archetype definition and the customer behavior are consistent.
Two studies, designed to triangulate
Nine customer sessions had participants submit a real project request and interact with seven pros on a prototype, each pro trained on a distinct response archetype (5 failure patterns, 2 success patterns) distilled from the 600-thread RQI investigation. Participants ranked and reasoned about pro responses at the end. Ten pro sessions tested three AI-assisted response concepts: C1 plain AI draft (closest to the v1 PRD scope), C2 structured draft with content/tone/length toggles, and C3 one-tap send from the leads list as a deliberate boundary test.
The two studies were designed to triangulate. Customer sessions stress-tested the behavioral content the tool needs to produce. Pro sessions stress-tested the workflow and control around how it gets produced and sent. The customer study was designed to check whether the response patterns from the RQI hold up when real customers interact with them. The pro study was a divergent-prototype study intended to surface behavioral limits — not to converge on a preferred UI.
Customer study
Each customer submitted one real project and interacted with seven pros trained on distinct response archetypes.
Pro study
Each pro reviewed three divergent AI-assist concepts. The set was designed to surface behavioral limits, not to pick a winner.
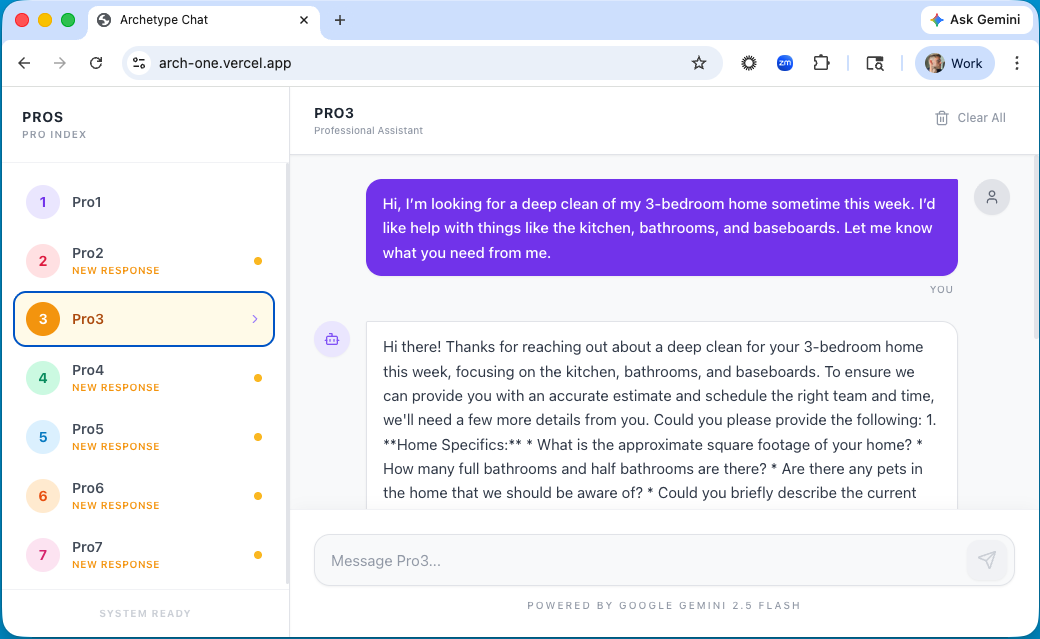
The three pro-side concepts were intentionally divergent, not incremental variations — each was included to answer a specific question.
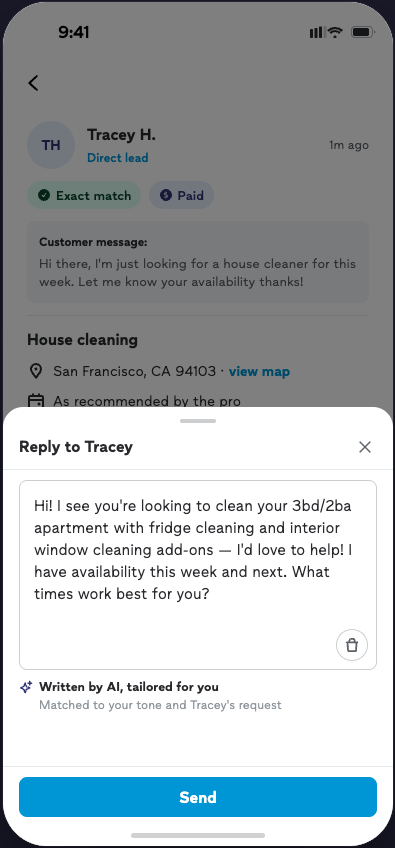
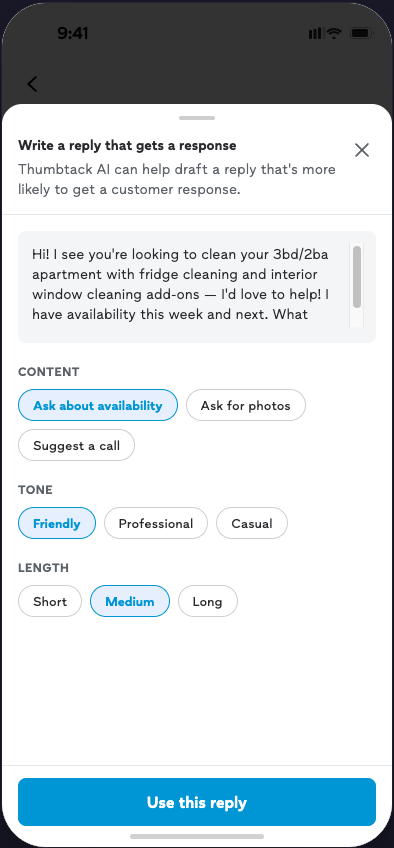
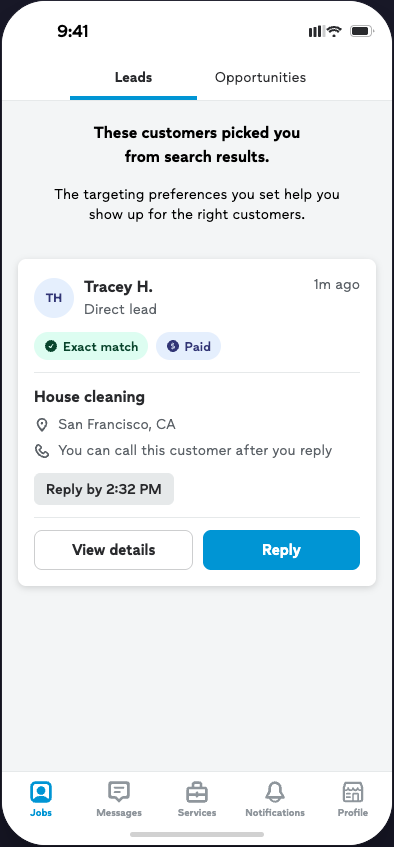
Directional findings. Core patterns replicated across studies. Not a causal claim about conversion — the MBT will test whether the draft moves customer reply rate.
How customers responded to the seven pro archetypes
Each of the 9 participants submitted a real project request, then interacted with seven simulated pros on a prototype — one pro per response archetype distilled from the RQI investigation.
What replicated from the RQI
- Effort-vs-confidence dynamic holds. When effort rises faster than confidence, customers defer. The prototype sessions let us watch this happen in real time: customers engaged warmly with Pro 3's thorough questions or dropped off sharply from Pro 5's high-effort intake bundle (photos + measurements + availability + budget up front).
- Acknowledgment + one bounded next step continues to outperform. Pro 7 (mirroring + one question + credibility signal) and Pro 6 (acknowledgment + one clarifying question) were the consistent winners.
- Early channel switching creates friction — but is not universally negative. Bryson read Pro 4's phone number offer as disintermediation and pushiness; Tanya (managing 23 properties) and Arpit read the same move as efficient and welcome. Timing and customer context moderate.
New or sharpened from customer concept testing
The same behavior reads as high-effort or low-effort depending on the customer.
Detail-oriented customers (Xuan, Melody, Barbara) treated Pro 3's thorough upfront questions as a competence signal — "any pro that's going to ask about all the details first strikes me as trustworthy." Others (NaQuia, Tanya) found the same pattern overwhelming and preferred Pro 7's middle path of lightweight mirroring plus staged questions. The effort-vs-confidence curve from RQI still holds; what varies is how quickly a customer crosses the confidence threshold and how they interpret the same pro behavior (a detailed intake list) as higher or lower effort. The implication is not "personalize to segment" (we can't reliably segment on this) but rather design the default to favor Pro 7's pattern, which was robust across both interpretations, and let detail-oriented customers self-select through follow-up.
Pro 7's middle-ground pattern was robust across both customer interpretations — those who read detailed intake as competence, and those who read it as overwhelm.
Listening is the strongest trust signal and the easiest to break.
Bryson stated Saturday after 11am as his availability; Pro 1 offered Friday 2pm and Monday 10am. That single miss was unrecoverable in his session — not a trust discount, a disqualification. Across sessions, ignoring a stated detail (time, location, a direct question) was the single most consistent path to being dropped.
This finding has a direct hook into the prompt work. Two specific data inputs currently missing or underweighted would address it: (1) the specific date/time selections the customer made — not just the binary "did they select availability." Chelsia flagged that V6 outputs are still generating "when works for you?" questions in threads where the customer has already provided windows. (2) Request-form photo data — photos and captions submitted in the request form. Where customers encode signal that doesn't appear in structured fields. Chelsia pointed to a concrete failure pattern already visible in production: pros asking "what exactly did you want me to install" when the answer was in a photo the model can't see. That's the Bryson failure mode, at scale, in live threads.
"Just listen to me. If I'm telling you Saturday after 11, why are you telling me Friday and Monday?"
— Bryson, customer session
Competitive shortlisting collapses the recovery window.
Once NaQuia and Arpit had identified 2–3 viable pros, they explicitly said they would not respond to the rest — even if those pros sent perfectly fine follow-ups. This is new information relative to the RQI framing, which positioned follow-up as a recovery mechanism. It still is a recovery mechanism in two places: (1) for pros whose first message wasn't seen (the ~25–30% visibility gap RQI established), and (2) for pros who made the shortlist on the first message and are continuing the conversation. Where it doesn't work is the middle case — pros whose first message was seen but didn't make the shortlist. For that group, there's no recovery path.
"Once I had 3 viable options… I probably would not respond to the others."
— NaQuia, customer session
Bot detection is already happening.
Jay wrote intentionally vague prompts because he detected LLM generation and wanted to see how each pro handled ambiguity. Customers flagged AI-sounding language through: perfect grammar, instantaneous response times, em-dashes, uniform structure across pros, and — most importantly — verbatim echoing of request-form details. Grace Boatwright's feedback on the v3 prompt output independently flagged the same signals.
If customers can detect AI in a research session, they can detect it in production. In-session, Jay and others didn't stop engaging, but the detection shifted how they read the platform: uniformity across pros got interpreted as Thumbtack sending form letters rather than pros responding, and that read showed up as lower trust in the platform rather than in any individual pro. Anti-redundancy becomes the difference between "Thumbtack helped me respond" and "Thumbtack is sending form letters on my behalf." There's a second mechanism worth flagging: when customers perceived a response as AI-generated, some reported they'd write back differently — shorter, less careful, less deferential than they would to a message they read as human. Detection doesn't just erode trust in the platform; it degrades the quality and care of the customer side of the conversation.
Pricing upfront is a significant trust builder — even when pros resist it.
Roslyn's session: Pro 6's price mention of a rough price range (not a firm quote) was the moment she moved that pro to top-of-list — it wasn't the number, it was the signal that the pro had enough confidence in the project scope to commit to a ballpark. Similar pattern showed up lightly in 2–3 other sessions where a directional price ("projects like this usually run $X–$Y") landed as expertise and decisiveness. Pros in the parallel study generally avoid pricing upfront because services are custom and they don't want to be held to a number sight-unseen. There's a real tension here that v1 won't resolve, but worth flagging: the customer-side appetite is for directional price clarity, not firm quotes, and that's less risky for pros than they assume. It may be worth re-examining the RQI (particularly the IRR) with this lens, since directional pricing may have been present but not tagged.
Seven archetypes, three outcomes
"There's nothing to respond to… the cognitive load is on me to carry on."
— Xuan, on Pro 2
What pros do when we hand them an AI draft
The C2 preference is about trust, not performance
Six of seven pros preferred C2 (structured draft with toggles) over C1 (plain draft). The obvious read is "pros want more control." The more precise read — which matters for product strategy — is that the toggles functioned as a trust mechanism more than a performance mechanism. Two signals point to this: (1) when pros saw C1, they didn't immediately ask for specific content edits; the desire for control surfaced once C2 made it visible. (2) When pros saw the C2 toggles, they didn't describe them in performance terms — they didn't say from experience that warm vs. direct or short vs. medium changes engagement. Some pros did want to change content (job-scope tiers, industry-specific options, brand messaging), but the dominant reaction was that toggles made them feel safer sending what was already there, not that they'd reliably produce a better message.
This matters because C2 can't ship in v1. The implication is not "build C2 anyway" — it's that the plain draft (C1) has to clear a higher bar on accuracy and voice than it would if pros had an in-context safety valve. If pros can't tweak quickly, they need to trust out of the box — which means output quality, voice detection, and verification affordances all get more weight.
An accuracy-verification affordance may substitute for control at lower cost. Grace (one of the pro participants) repeatedly toggled back to the lead details before sending, to verify the draft was accurate to what the customer said. That toggling behavior is friction — pros leaving the compose moment to do an accuracy check — but it points to the underlying anxiety: "is this draft accurate to what this customer said?"
"It's a worthless tool if I can't have some input as to what it's generating."
— Michael, pro session
C3 was a unanimous rejection — with two overlapping reasons
Every pro said they'd always view lead details before sending. But the reason varied and both reasons matter:
- Category-driven rejection. Don (caricature artist), Monica (catering), and Emmanuel (commercial flooring) rejected C3 because their businesses sell specific dates or spaces — they can't commit without verifying availability.
- Universal rejection. Even pros without that constraint (Mark, Dan, Grace) said they'd always check the lead first.
This validates keeping the compose flow inside the lead details view rather than at the leads-list level — already the PRD direction. Worth flagging: C3 surfaced a secondary insight — pros value the view-details step as a decision-quality moment. Reviewing the lead details isn't just about gathering information for the message; it's the moment pros decide if the lead is worth their time, whether they can actually do the job, and how to qualify it before committing. Removing that step removes a checkpoint they rely on.
Too fast. No context.
Context first.
The compose moment belongs here, not there.
"It's a trap to reply too fast."
— Grace, pro session
Voice, differentiation, and "AI-ed" language
Mark immediately read the v1 draft as "AI-ed." Don flagged em-dashes as an AI tell. Dan (Minnesota Headshots): "No one would ever write this stuff… that immediately takes confidence away." The concern cuts two ways:
- Pro-side: if pros perceive the draft as AI-ish, they'll edit heavily (cost: adoption friction) or disable the feature entirely (cost: reach).
- Customer-side: pros also worry that if every pro sends similar AI-drafted responses, customers will notice and trust the platform less — not just any individual pro. Dan flagged this as a platform-level risk.
This maps directly onto Grace Boatwright's v3 prompt feedback (excessive mirroring, overly formal language, uniformity across pros). The two data streams are pointing at the same thing from opposite ends — customers detect uniformity, pros detect uniformity, and both interpret it as a quality/authenticity failure.
"If all my competitors are clicking the same button, there is no differentiation."
— Mark, pro session
Next-step defaults and the tension with RQI priors
Pros have strong opinions about what the next step should be, and they almost all default to phone call. The RQI investigation positioned call-first escalation as a failure pattern when it outpaces confidence. The pro sessions show that call-first isn't just a habit — it's a rational risk-management move in pro workflows (qualify lead, reduce wasted spend, move off-platform to control pacing). This is also what multiple internal functions actively coach — Sales, NAMs, and the pro advisory board all teach phone-first because the data supports it on the pro-business side. The customer research doesn't contradict that directly; it sharpens it. Call-first converts for customers who are ready for that step and backfires for those who aren't. The customer sessions show that call-first works for some customers and breaks for others, with timing as the moderator.
v1 descopes pro preferences for next-step type. The research suggests this is the right call for the initial MBT — we need to learn what works for customers before opening up pro customization — but we should plan to surface next-step control relatively quickly as a fast-follow, and communicate to pros that the tool is defaulting to what the data says works, not overriding their judgment.
What changes for the plan
The moves that follow from both studies together. These are the changes to v1 scope and priority that the research supports.
1. The plain draft needs to nail four things to be defensible in v1
Because we're shipping without toggle-based control, the default output has to earn trust without a safety valve.
Lightweight mirroring
1–3 high-signal details from free-text, not a form transcript. Varied across pros.
Next step as a question that lowers reply effort
A specific, scoped question is easier to reply to than an open one or a declarative ("I can schedule Thursday"). Anchor on a concrete detail the customer gave, narrow what's being asked, and put the ball in their court.
No boilerplate credibility, demonstrate competence through job-specific questions
They've already seen your reviews. Credibility comes from asking a question that shows you understood the specific job — like mentioning 60-gallon vs. 40-gallon water heater, not "do you have any other questions?"
Voice variation across pros
Cheapest anti-redundancy move for pros without history. For pros with history, voice patterns from their own past messages are a stronger differentiator than structural variation alone.
The PRD's data inputs table now excludes pro bio, years in business, licenses, service categories, past jobs, targeted categories, and quote sheet — with the explicit rationale that these were generating sales-y content and that customers have already seen this context on the pro's profile page. Credibility is being engineered as behavioral (through the question asked), not through self-promotional language in the message itself. V7 of the prompt operationalizes lightweight mirroring (1–3 details) and one bounded next step as a question.
2. Anti-redundancy should be P0, not P1
- Customers compare messages in parallel and will detect uniform output.
- Pros won't adopt a tool that flattens their differentiation.
- Cheapest way in is to vary which details get mirrored and the way each response is structured — not to rewrite each pro's voice from scratch, which is costly.
- Varying next-step substance is part of the anti-redundancy lever, not separate from it. If three pros responding to the same lead all default to "want to hop on a call?" they read as interchangeable even if the rest of the message varies. Different next-steps (clarifying question, scheduling, call) across pros may matter more for differentiation than getting the single "right" next step.
3. Pros need an in-context way to verify draft accuracy
The pro user need: when a pro reads an AI draft, the immediate question is "is this accurate to what this customer said?" In session, multiple pros toggled back to the lead details mid-compose to check. That toggling behavior is friction — the trust check is real, but the workflow forces pros to leave the compose moment to do it.
v1 doesn't address this directly. C2's toggles incidentally created a sense of accuracy control (part of why preference for C2 was about trust rather than performance), but C2 isn't shipping. Without a verification affordance, the plain draft has to clear a higher accuracy bar to compensate, and pros who can't trust the output quickly will edit heavily or disable the feature. The underlying need — verify accuracy without leaving the compose flow — is real and not currently met.
4. The pro-side communications layer matters more than it looks
This connects directly to Cailee's GTM work. Key moves:
- Chelsia's original framing of the NUX goal (influence pro behavior and understanding, not blind adoption) aligns with what pros told us.
- Pros who don't understand why the tool is making a particular choice will override toward their own default (usually a call).
- The 4/21 legal review removed the heavy AI-disclosure requirement, which loosens the legal case for a NUX but strengthens the behavioral one.
Where the research lands on the NUX decision
A P1 lightweight education NUX has been scoped (not launch blocking). What the research speaks to is less whether to have one and more what it should carry and where it should live. Session evidence pointed consistently to awareness before first exposure — Grace, Michael, Monica, and Mark all expressed wanting advance notice about what the tool does, not a pop-up at the compose moment. The distinction matters: preparedness can be delivered through Cailee's GTM emails/pushes; a compose-level surface risks crowding the trust-sensitive moment when the pro is already forming an opinion about the draft itself.
Research lean: consolidate awareness into the GTM layer; if an in-product surface is valuable on top of that, scope it upfunnel (jobs tab, lead detail) rather than at compose.
Top three behavioral rationales for the GTM layer
(Internal note, not for pro-facing GTM): A fourth behavioral pattern — that whether a call vs. a question converts depends on the customer, not the pro's default — is a real finding from the research, but it's not yet actionable as pro-facing guidance. Telling pros "it depends" without telling them when to call vs. when to ask a question creates more confusion than clarity. We need to figure out the call-vs-question strategy first (likely informed by MBT data) before guiding pros on it. For v1 GTM, lead with the three above.
Cailee's campaign brief submitted 4/23 incorporates this framing.
5. Separate signal restoration from intervention design — visibility still matters
The RQI investigation's hard constraint — ~25–30% of pro responses are never viewed — still holds and is not addressable via response quality. This work should not be measured against outcomes in threads where the customer never saw the response. Primary success metric (% projects with customer reply within 24hr of first pro response) correctly gates on the response existing and being seen; worth confirming the measurement excludes unseen messages cleanly.
Two prompt input gaps the research pointed to — and where we are on each
Research surfaced two specific prompt input gaps that map to the Bryson-style listening failure: specific date/time selections the customer made (not just "did they provide availability"), and request-form photo data (photos and captions submitted in the request form). Status as of the V7 prompt build:
Closing the remaining gap is what separates a draft that asks "when works for you?" in a thread where the customer has already given their windows, from a draft that uses those windows in the next-step question.
Both are on the V7 track ahead of April 29 prompt finalization.
What this doesn't settle
Open tensions
These are tensions the research surfaced but doesn't resolve. They need product/strategy judgment, not more research (for now).
Do we invest in toggles post-v1 primarily to drive adoption (trust) or because they measurably improve outputs (performance)? The research suggests the former. If that's right, the investment case is different — it's an adoption lever, not a content lever.
Multiple internal functions (Sales, National Account Managers, Pro Advisory Board, frontline coaches) currently teach pros to call-first or channel-blast, based on data that it wins pro business. The customer research shows call-first works for some customers and breaks for others, with timing and context as moderators. These aren't necessarily contradictory — winning pro business and creating a good customer experience get measured at different points in the funnel, but they are in tension, and the tool is landing in the middle of it. If the MBT shows that asking a follow-up question gets more customer replies than suggesting a call, should the draft default to the question even when pros (and their coaches) would have chosen a call? Becomes a cross-functional alignment question, not just a product one.
This also layers into the post-v1 controls question above. If MBT data points to question-first as the higher-converting default but pros resist it, the path forward may look like the C2 pattern — give pros explicit control over next-step type (call vs. question vs. scheduling) as an adoption lever rather than enforcing a single default. Same trust-vs-performance logic: the toggle wouldn't necessarily produce a better message, but it would let pros adopt the tool without overriding their judgment.
If we vary outputs enough to avoid uniformity, some variations will be worse than others. The customer research suggests variance has real value — customers used the differences to evaluate fit — but it's a trade we haven't explicitly made.
Customer-side pull is real; pro-side resistance is real. We also currently lack the data to do this well — directional pricing reliable enough to surface in a draft (by category, scope, geography) isn't readily available in our systems. v1 doesn't need to resolve any of this; post-MBT does.
What's out of scope for this synthesis
To be explicit about what this doc isn't claiming.
- Not a causal claim about conversion. Both studies were designed to check whether response patterns hold up, not to run an A/B test. The MBT will test whether the draft actually moves customer reply rate.
- Not a scale-readiness assessment. v1 is unlikely to be scale-ready in its current form and a v2 iteration is likely. This doc informs what v1 needs to clear to be a useful learning test.
- Not an endorsement of Pro 7's specific language. The win was about pattern (lightweight mirroring + question + signal), not wording. The prompt work should aim at the pattern, not the text.
- Not a complete picture of the visibility layer. The RQI investigation established unseen messages as a structural gate; this work builds on that but doesn't address it.
What happens next
Recommended next steps
Appendix
Archetype performance across customer sessions (directional)
| Archetype | Pattern | Net reception |
|---|---|---|
| Pro 1 — No acknowledgment | Friendly but generic; no mirroring of stated details | Generally dropped by most participants. Becomes disqualifying when stated details (time, location) are ignored. Lower harm ceiling than Pro 2 or Pro 5 because at least it doesn't actively contradict. |
| Pro 2 — No clear next step | Acknowledges request but ends without a clear action | Near-universal hard failure. Cognitive load transfers to the customer to figure out the next move. Xuan's "there's nothing to respond to" quote captures this exactly. |
| Pro 3 — Full intake | High-effort upfront: multiple detailed questions in first message | Bimodal. Detail-oriented participants (Xuan, Melody, Barbara) found it thorough and trustworthy. Efficiency-focused participants (NaQuia, Tanya) found it overwhelming. Not universally safe. |
| Pro 4 — Call-first | Offers phone number or call invite in first message | Bimodal. Efficiency-focused customers read it as professional and time-saving. Others read it as pushy or disintermediating. Timing and customer context are the key moderators. |
| Pro 5 — Question-ignoring | Redirects away from a question the customer directly asked | Disqualifying. Same family of failure as Pro 1, but more active — it doesn't just skip acknowledgment, it ignores what the customer directly asked. Hardest failure outside of Pro 2. |
| Pro 6 — Acknowledgment + one question | Mirrors 1–2 specific details, asks one bounded clarifying question | Strong and consistent. Worked across most participant types. No disqualifying moments. Low effort to respond. Robust second-best. |
| Pro 7 — Mirroring + question + credibility signal | Lightweight mirroring, one question, implicit credibility via question quality | Most robust across all 9 sessions. The only archetype that consistently worked across both detail-oriented and efficiency-focused customers. Credibility signal landed through pattern, not through self-promotional language. |
Verbatims referenced throughout
Expand quote inventory
"Once I had 3 viable options… I probably would not respond to the others."
NaQuia — customer session"Just listen to me. If I'm telling you Saturday after 11, why are you telling me Friday and Monday?"
Bryson — customer session"Any pro that's going to ask about all the details first strikes me as trustworthy."
Xuan — customer session"There's nothing to respond to… the cognitive load is on me to carry on."
Xuan — customer session, on Pro 2"It's a worthless tool if I can't have some input as to what it's generating."
Michael — pro session"You're giving me the control."
Turk — pro session"It's a trap to reply too fast."
Grace — pro session"If all my competitors are clicking the same button, there is no differentiation."
Mark — pro session"No one would ever write this stuff… that immediately takes confidence away."
Dan — pro session"I like to be prepared for changes that are coming."
Grace — pro session, on advance notice"If the data showed that, that would change how I use the tool."
Jen — pro session, on call-first default vs. data-driven default